
The late, great, John Lewis is well known for a quote about getting into trouble.
Never, ever be afraid to make some noise and get in good trouble, necessary trouble.
It’s time to start some good trouble.
Anyone who knows me, reads this blog, or follows me on Twitter, is well aware I have been a proponent of CVE Identifiers for a very long time. I once assigned CVE IDs to most open source security vulnerabilities. I’ve helped more than one company and project adopt CVE IDs for their advisories. I encourage anyone who will listen to adopt CVE IDs. I’ve even talked about it on the podcast many times.
I also think it’s become clear that the generic term “CVE” and “Vulnerability” now have the same meaning. This is a convenient collision because the world needs a universal identifier for security issues. We don’t have to invent a new one. But it’s also important we don’t let our current universal identifier continue to fall behind.
For the last few years I’ve been bothered by the CVE project as it stands under MITRE, but it took time figure out why. CVE IDs under MITRE have stalled out, in a time when we are seeing unprecedented growth in the cybersecurity space. If you aren’t growing but the world around you is, you are actually shrinking. The realty is CVE IDs should be more important than ever, but they’re just not. The number of CVE IDs isn’t growing, it’s been flat for the last few years. Security scanners and related vendors such as GitHub, Snyk, Whitesource, and Anchore are exploding in popularity and instead of being focused on CVE IDs, they’re all creating their own identifiers because getting CVE IDs often isn’t worth the trouble. As a consumer of this information, it’s unpleasant dealing with all these IDs. If nothing is done it’s likely CVEIDs won’t matter at all in a few years because they will be an inconsequential niche identifier. It’s again time for the Distributed Weakness Filing project to step in and help keep CVE IDs relevant.
The problem
I want to start with a project I’ve been working on for a long time. I called it cve-analysis, it’s public on GitHub, you can give it a try. Basically we take the NVD CVE data (which also includes past Distributed Weakness Filing data), put it in Elasticsearch, then look at it. For example here is a graph of the published CVE Identifiers with associated data by year:

Anyone with a basic understanding of math will immediately know this is not a graph showing growth. It’s actually showing a steep decline. While the last few years are in what looks like minor decline, the reality is the world around CVE IDs is growing exponentially, so while CVE IDs are shrinking slowly on the graph, in the greater world of expanding cybersecurity, it’s shrinking very quickly. That graph should look like more like this
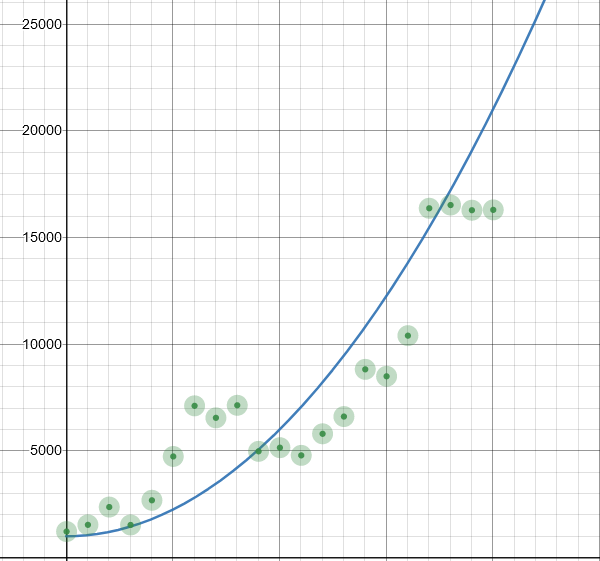
I’ve left out 2021 for the purpose of the fit line. To be honest, I think the fit line should be more aggressive but I kept it conservative to avoid the fit line becoming a point of contention. If CVE IDs were growing properly, we should be seeing more than 23,000 CVE IDs in 2021. Unless something changes we’ll probably see slightly less than 16,000.
I want to add a note here about this data. I am showing the CVE IDs based on the year in the ID. So CVE-2020-0001 will be under the 2020 graph, no matter when it actually gets assigned. It is common for a 2020 ID to be assigned in 2021 for example. There is not a public source of reliable data on when an ID was assigned. The data I could find did not look drastically different, so I picked the simple option.
I could go on pointing out problems, but I think the number of IDs is an easy problem to understand and helps show other latent problems. The number of IDs should be growing, but it’s not. CVE IDs, as currently managed under MITRE, are shrinking in both number and relevance. We need CVE IDs more than ever, but the CVE Project as managed by MITRE has change very little in the last 22 years. The MITRE CVE world of 1999 isn’t drastically different from the MITRE CVE world of 2021. But the security world of 2021 looks nothing like 1999 did.
How did we get here?
I don’t think there will ever be one simple reason the MITRE CVE project ended up where it did. I want to bring us back to somewhere around 2014. Let’s start with this tweet
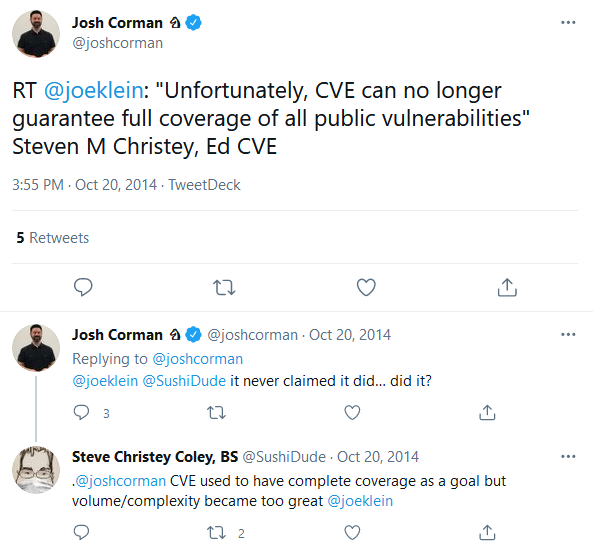
I don’t think anyone would fault the CVE project for this. Every project has to constrain itself, infinite scope is impossible. If we look at the CVE ID graph around 2014 we can see it was in a bit of a slump, the data shows us inconsistent growth from year to year.
One big reason for this struggled growth is what I would describe the legacy CVE data as “artisanal security”. All of the IDs are hand crafted by humans, humans don’t scale. The data is very prose instead of being something machine readable. If you’ve ever tried to get an ID assigned to something, it can be a very overwhelming task. Take a look at this GitHub issue if you want an example. From my experience this sort of back and forth is not an exception, it’s the norm, especially for beginners. Most people give up. This sort of behavior might have been considered OK in 1999. It’s not 1999 anymore.
This sets us up for 2016 and what looked like things were going to get better. Start with this article by Steve Ragan, it’s still a great read today, you won’t regret reading it. Steve summarizes some of the issues the project was seeing. They were missing a lot of vulnerabilities. There was quite a dust up around CVE IDs in 2016. It became suddenly obvious the project wasn’t covering nearly as much as it should be. I mean, there were only 22 CVE Naming Authorities (CNA) in 2016 (remember, artisanal security). A CNA is an organization that has been given permission to assign IDs to a very specific set of applications. CNAs are expected to stay in their lane. From 1999 to 2016. In 17 years they only picked up 22 organizations to assign CVE IDs? That’s slightly more than one per year. At the time I’m writing there are 159 CNAs. It’s still an outdated model with an unacceptably low number.
If we look again pull up our graph
We can see a noticeable uptick in 2017. For most of us paying attention this was what we were waiting for, the CVE project was finally going to start growing!
And then it didn’t.
There are a lot of reasons for this stagnation, none of which are easy to explain. Rather than spending a lot of time trying to explain what’s happening, I will refer to this 2020 article by Jessica Haworth. The point in that article is that the CNA system lets a CNA decide what should get an ID. This is sort of how security worked in 1999 when security researchers were often treated as adversaries. This is no longer the case, yet researchers have no easy way to request and use their own CVE IDs. If you report a vulnerability to an organization, and they decide it doesn’t get a CVE ID, it’s very difficult to get one yourself. So many researchers just don’t bother.
Right about here I’m sure someone will point out that a CVE request form exists for just this sort of thing! Go look at it https://cveform.mitre.org, I’ll let you make up your own mind about it.
The Solution
Fixing any problem is difficult. This is where a friend of mine enters our story. What is wrong with, and how to fix CVE IDs is a topic Kurt Seifried has spent a great deal of time thinking about and working on. One thing that happened in 2016 to try to get CVE back on the right path was the DWF project. The idea was to make CVE data work more like open source. We can call that DWF version 1. DWF version 1 didn’t work out. There are many reasons for that, but the single biggest is that DWF tried to follow the legacy CVE rules which ended up strangling the project to death. Open source doesn’t work when buried under artificial constraints. Open source communities need to be able to move around and breath so they can thrive and grow.
After a few years, a lot of thought, and some tool development, this leads us to DWF version 2. The problem with version 1 is it wasn’t really an open source community. Version 1 of DWF was really just a GitHub repository of artisanal CVE data that Kurt single-handedly tried to meet the constraints of legacy CVE. He should be commended for sticking with it as long as he did, but humans don’t scale. DWF version 2 sheds the yoke of legacy CVE and creates an open community anyone can participate in and is on the path of 100% automated CVE IDs. There is no reason you shouldn’t be able to get a CVE ID in less than ten seconds.

The very first argument you will hear is going to be one of quality. How there’s no way the community can create IDs that will match the hand crafted quality of legacy CVE IDs! Firstly, that’s not true. Remember the cve-analysis project? We can look into all of these claims. Data beats conjecture, we have data. Here’s one example of what I’ve found. There are a lot of examples like this, I’m not going to nitpick them all to death. Let’s just say, it’s not all master craftsman quality descriptions. There are a lot of demons hiding in this data, it’s not as impressive as some would like you to believe.
And the second, far more important point, is this argument was used against Wikipedia. Remember encyclopedias? Yeah, they spent a lot of time trying to discredit the power of community. Community already won. Claiming community powered data is inferior is such an outdated way of thinking it doesn’t even need to be deconstructed in 2021.
So what is DWF?
The TL;DR is DWF is a community driven project to assign DWF CVE IDs to security issues. Part of the project will be defining concepts like what is a “security issue”? This is 2021, not 1999 anymore. The world of security vulnerabilities has changed drastically. We need to rethink everything about what a vulnerability even is. The most important thing is we do it as a community and in public. Communities beat committees every day of the week!
This is not a project condoned by MITRE in any way. They are of the opinion they have a monopoly on identifiers that follow the CVE format. They called us pirates. And even tried to submit pull requests to change how the DWF project works. This is the “good trouble” part of all this.
There is a website at https://iwantacve.org that lets you request an ID. You enter a few details into a web form, and you get a candidate, or CAN ID. A human then double checks things, approves it, then the bot flips it to a DWF CVE ID assuming it looks good. Things generally look good because the form makes it easy to do the right thing. And this is just version one of the form! It will keep getting better. If you submit IDs a few times you will get added to the allowlist and just get a DWF CVE ID right away skipping the CAN step. Long term there won’t be any humans involved because humans are slow, need to sleep, and get burnt out.
Here is the very first ID that was assigned CVE-2021-1000000. We were still debugging and testing things when the site was found and used by a researcher, so our timeline sort of got thrown out the window, but in the most awesome way possible! It’s very open source.
The project can be broken down into three main pieces. The workflow, the tooling, and the data.
The workflow is where conversations are meant to be held. Policies should be created, questions asked, new ideas brought up. It’s just a GitHub repo right now. The community will help decide how it grows and evolves. Everything is meant to happen in public. This is the best place to start out if you want to help. Feel free to just jump in and create issues to ask questions or make suggestions.
The tooling is where the two applications live that currently drive everything. Right now this is a bot written in python and a the web form written in Node.js. The form is what drives the https://iwantacve.org website. The bot is how data gets from the form into the GitHub data repo. Neither is spectacular code. It’s not meant to be, it’s an open source project and will get better with time. It’s good enough.
The data is where the DWF json is held. There’s not a lot to say about this one, I think it’s mostly self explanatory. The data format will need to be better defined, but that conversation belongs in the workflow.
The purpose of DWF is to build a community to define the future of security vulnerabilities. There is much work to be done. We would love it if you would lend a hand!